岡田 康介
名前:岡田 康介(おかだ こうすけ) ニックネーム:コウ、または「こうちゃん」 年齢:28歳 性別:男性 職業:ブロガー(SEOやライフスタイル系を中心に活動) 居住地:東京都(都心のワンルームマンション) 出身地:千葉県船橋市 身長:175cm 血液型:O型 誕生日:1997年4月3日 趣味:カフェ巡り、写真撮影、ランニング、読書(自己啓発やエッセイ)、映画鑑賞、ガジェット収集 性格:ポジティブでフランク、人見知りはしないタイプ。好奇心旺盛で新しいものにすぐ飛びつく性格。計画性がある一方で、思いついたらすぐ行動するフットワークの軽さもある。 1日(平日)のタイムスケジュール 7:00 起床:軽くストレッチして朝のニュースをチェック。ブラックコーヒーで目を覚ます。 7:30 朝ラン:近所の公園を30分ほどランニング。頭をリセットして新しいアイデアを考える時間。 8:30 朝食&SNSチェック:トーストやヨーグルトを食べながら、TwitterやInstagramでトレンドを確認。 9:30 ブログ執筆スタート:カフェに移動してノートPCで記事を書いたり、リサーチを進める。 12:30 昼食:お気に入りのカフェや定食屋でランチ。食事をしながら読書やネタ探し。 14:00 取材・撮影・リサーチ:街歩きをしながら写真を撮ったり、新しいお店を開拓してネタにする。 16:00 執筆&編集作業:帰宅して集中モードで記事を仕上げ、SEOチェックやアイキャッチ作成も行う。 19:00 夕食:自炊か外食。たまに友人と飲みに行って情報交換。 21:00 ブログのアクセス解析・改善点チェック:Googleアナリティクスやサーチコンソールを見て数字を分析。 22:00 映画鑑賞や趣味の時間:Amazonプライムで映画やドラマを楽しむ。 24:00 就寝:明日のアイデアをメモしてから眠りにつく。
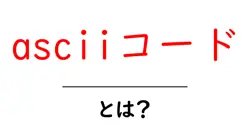
文字列検索・とは?
文字列検索とは、文章や記録の中から、ある決まった「文字列」を探し出す作業のことです。日常生活にもITの世界にも、広く使われます。例えばテキストの中から名前を探したり、商品コードを見つけたりします。
文字列とは何か
文字列は文字が並んだ「ひとつの文のようなもの」です。英数字や日本語、記号を順番に並べて作られ、プログラミングでは 文字列はデータの一種として扱われます。
文字列検索の基本概念
文字列検索では「パターン(探したい文字列)」と「テキスト(探す対象)」を用意します。目的は、テキストの中にパターンが現れる位置を見つけ出すことです。見つかった場合はその位置を返したり、出現回数を数えたりします。
日常生活の例
例: 友だちの名前がどこに書かれているか探す、長いメールの中で特定のフレーズを探す、など。ここでは「猫」という文字列を、文字列「私は猫が好きです。猫はかわいい。」の中から見つける実例を使います。
プログラムでの例(簡易)
以下は中学生にもわかる形の、疑似コード風の説明です。実際のプログラミング言語を使わなくても、考え方を理解するのに役立ちます。
例: text = '私は猫が好きです。猫はかわいい。'; pattern = '猫'; if pattern in text: print('見つかった')
実用的なポイント
文字列検索を速くするコツには、パターンの前処理や、アルゴリズムの選択が含まれます。単純な方法は誰でもすぐに思いつきますが、長いテキストや複数回の検索になると、時間が大きく変わってきます。
よく使われるアルゴリズムの紹介
ここでは難しく感じる人も多いので、名前だけでも覚えておくと役に立ちます。Naive(単純探索)、KMP(Knuth–Morris–Pratt)、Boyer–Mooreなどの言葉を知っておくと、検索の話題になったときに話がスムーズです。
学習の手順
初めから難しい数式に飛びつくより、次の順番で進めるとよいです。1) テキストの中から探したい文字列を決める。2) テキストとパターンの関係を観察する。3) 簡単な実装から試し、結果を確認する。4) 大きなデータには効率の良いアルゴリズムを検討する。
実務での活用とまとめ
文字列検索は情報を見つけ出す基本技術です。Web検索の裏側、ファイル内の文字列探索、データ分析の前処理など、多くの場面で役立ちます。初心者はまず「パターン」と「テキスト」の関係を理解することから始めましょう。
表による比較
まとめの一言
このような仕組みを知っておくと、検索に強いプログラミングを組むことができます。初心者はまず「パターン」と「テキスト」の関係を理解することから始めましょう。
文字列検索の同意語
- テキスト検索
- テキストデータ全体の中から、目的の文字列を探す一般的な方法。全文検索や部分一致、正規表現などを含む広い意味で使われることが多い。
- 文字列マッチング
- 二つの文字列が一致するかを判定する基本的な手法。アルゴリズム例としてKMP、Boyer–Moore、Rabin–Karpなどが用いられる。
- パターンマッチング
- 特定のパターン文字列とデータの部分一致を探す技法。正規表現や簡易なワイルドカード検索を含むことが多い。
- 正規表現検索
- 正規表現で定義したパターンに一致する文字列を検索・抽出する方法。
- 正規表現マッチング
- 正規表現を用いて文字列の照合を行い、一致箇所を見つけ出す手法。
- 部分文字列検索
- 長い文字列の中に、指定した部分文字列が現れる箇所を探す手法。
- 部分一致検索
- 検索クエリの一部が対象データと一致する箇所を探す方法。
- 完全一致検索
- 検索語句とデータ内の文字列が完全に一致する箇所を探す方法。
- 近似文字列検索
- 文字列が似ているものを検索する方法。スペルミスや誤差を許容する場合に用いられる。
- 文字列照合
- 文字列の等価性を照合・検証する処理。完全一致だけでなく部分一致も含むことがある。
- 文字列探索
- 文字列を対象に、目的のパターンを探し出す広い意味の検索。
- 全文検索
- 文書全体を対象に、キーワードの出現箇所を高速に検索する技術。インデックス(逆引きインデックス)を用いることが多い。
- ワイルドカード検索
- ワイルドカード文字(例: ?、*)を使って柔軟に文字列を検索する方法。
文字列検索の対義語・反対語
- 文字列検索の対義語
- データ中の文字列を探す行為を行わないこと、または文字列を検索対象にしない状態。
- 非文字列検索
- 文字列以外のデータ(数値・日付・画像など)を検索すること、または文字列検索を回避する意味。
- 検索なし
- データを検索して結果を得る行為を全く行わない状態。
- 無検索モード
- 検索機能をオフにして、探索を行わない設定。
- 観察のみ
- データを観察・確認するだけで、文字列を積極的に探さない行動。
- 参照のみ
- データを参照するだけで、文字列の検索作業を伴わない状態。
- 数値検索
- 文字列ではなく数値データを対象に検索することの対比的な活動。
- 画像検索
- 画像データを対象に検索すること。文字列検索の代わりにビジュアル要素を探す行為。
- メタデータ検索
- 本文の文字列ではなくファイルのメタデータを検索すること。
- 完全一致検索
- 検索語とデータが完全に一致するかを調べる方法で、部分一致検索の対比として使われることがある。
- 単語検索
- 文字列全体ではなく、単語単位で検索する方法で、柔軟な文字列検索の対比として用いられることがある。
文字列検索の共起語
- 検索アルゴリズム
- 文字列検索を実現するための方法論。KMP法、Rabin–Karp法、BM法などが代表例です。
- 文字列比較
- 二つの文字列を一文字ずつ照合して一致を判定する基本操作。大文字小文字の区別や文字コード設定の影響を受けます。
- 部分一致
- 検索語が対象文字列の一部に一致する状態。部分文字列を探す場合に使われます。
- 完全一致
- 検索語と対象文字列が正確に同じ場合を指します。
- 正規表現
- パターンを使って文字列を検索・抽出する強力な手法。ワイルドカードより柔軟です。
- 正規表現エンジン
- 正規表現を解釈して検索を実行するソフトウェア。例として PCRE、RE2、Java など。
- ワイルドカード検索
- はてな記号やアスタリスクを用いて柔軟にマッチさせる検索方式です。
- 部分文字列検索
- 連続した文字列の一部を探す基本操作です。
- パターンマッチング
- 特定のパターンと文字列の一致を調べる一般的な概念です。
- テキスト検索
- テキストデータ全体から特定の語句を探す作業の総称です。
- 全文検索
- 大規模な文書コレクションの全文を対象に検索する機能。インデックスが重要です。
- インデックス
- 検索を速くするためデータを整理・索引付けするデータ構造・技術です。
- 検索速度
- 検索処理の応答時間。データ量とアルゴリズム選択で左右されます。
- 時間計算量
- アルゴリズムの処理量を入力長に対する関数として表す指標です。
- 大文字小文字の区別
- 検索時に大文字と小文字を区別するかどうかの設定です。
- Unicode対応
- 多言語文字を正しく扱えるよう文字集合をサポートすることです。
- 文字コード
- UTF-8 などの文字を数値に変換する規則。検索時は揃えると誤検出を減らせます。
- SQLのLIKE演算子
- SQL でパターン一致検索を行う機能。ワイルドカードと同様の使い方をします。
- テキストインデクシング
- テキストを索引付けして高速検索を実現する工程です。
- 全文検索エンジン
- Elasticsearch や MeiliSearch など、全文検索機能を提供するソフトウェアです。
- 自然言語検索
- 意味や文脈を考慮して検索を改善するアプローチです。
- 文字コード変換
- 検索時に文字コードの不一致を解消する処理です。
- 正規表現のメタキャラクター
- ドット、アスタリスク、プラス、クエスチョン、角括弧など、特別な意味を持つ記号群です。
- マッチングアルゴリズム
- パターンと文字列の適合を計算する手法の総称です。
- クエリ最適化
- 検索クエリを効率よく実行するための工夫です。
- 結果ランキング
- 検索結果を関連性順に並べるための評価指標です。
- インクリメンタル検索
- 入力中に段階的に結果を更新して返す検索方式です。
- ファイル検索
- コンピュータ内のファイル名や内容を検索する際に使われる共起語です。
- コード検索
- ソースコード内の文字列やシンボルを検索する場面で使われます。
- KMP法
- Knuth–Morris–Pratt 法。前方照合を効率化する文字列検索アルゴリズムの一つです。
- BM法
- Boyer–Moore 法。大規模テキストからパターンを高速に見つけるアルゴリズムです。
- Rabin–Karp法
- ハッシュを使ってパターンとテキストの一致を高速に判定するアルゴリズムです。
- ヒット数
- 検索条件を満たす一致の総数を表します。
- ヒット率
- 全体に対する一致の割合を表す指標です。
文字列検索の関連用語
- 文字列検索
- テキストの中から特定の文字列を探し出す基本的な行為。全体の文書内で目的の語句を見つけることを指す。
- 部分一致検索
- テキストの任意の位置に、指定した文字列が含まれているかを判定する検索。
- 完全一致検索
- 検索語とテキスト全体が完全に一致する場合のみヒットとする検索。
- 全文検索
- 文書全体を対象に、語句やフレーズを高速かつ正確に検索する技術。
- 正規表現
- 柔軟なパターンで文字列を検索する方法。繰り返しや任意文字などの表現を使える。
- 正規表現エンジン
- 正規表現パターンを解釈してテキストと照合するソフトウェアの仕組み。
- ワイルドカード検索
- "*" や "?" などを用いて任意の文字列を表す検索。
- 近似検索
- 誤字・表記ゆれを許容して、近い文字列を検索結果として返す手法。
- 編集距離
- 2つの文字列間の挿入・削除・置換の最小操作数を測る指標。
- Levenshtein距離
- 挿入・削除・置換の回数を数える、編集距離の代表的な指標。
- Damerau-Levenshtein距離
- 挿入・削除・置換に加え、転置もカウントする拡張版の編集距離。
- Jaro-Winkler距離
- 文字列の先頭部分の一致を重視して類似度を評価する指標。名前検索などで有効。
- KMPアルゴリズム
- Knuth–Morris–Pratt アルゴリズム。前方情報を利用して長いパターンを高速に探索。
- Boyer-Mooreアルゴリズム
- パターン文字列を大きくスキップしながら高速に検索するアルゴリズム。
- Rabin-Karpアルゴリズム
- ハッシュ値を用いて一致を効率化するアルゴリズム。多数のパターンにも適用可能。
- Aho-Corasickアルゴリズム
- 複数パターンを同時に線形時間で検索できる自動機ベースのアルゴリズム。
- Trie(トライ)木
- 文字列を木構造で表現し、先頭からの検索を高速化するデータ構造。
- サフィックスツリー
- 長文の全サフィックスを表す木構造。部分文字列検索を高速化。
- サフィックス配列
- 長文の全サフィックスを辞書順に並べた配列。高速な部分文字列検索の基盤。
- 全文検索エンジン
- 大量のテキストを高速で検索するための検索エンジン。例:Elasticsearch、Luceneなど。
- インデックス
- 検索を高速化するためのデータ構造。語句と文書の対応を保存。
- 逆インデックス
- 語句から文書を導くデータ構造。検索エンジンの中核。
- 全文検索機能/全文検索エンジンの実装例
- データベース内での全文検索機能(例:PostgreSQLのto_tsvectorなど)。
- トークン化
- テキストを意味のある単位(トークン)に分割する前処理。検索の精度を左右。
- トークン
- 検索で扱う最小単位の語・語形・語幹など。
- 正規化
- 文字列を比較しやすく揃える前処理全般。
- Unicode正規化
- 文字の結合・分解を標準化する処理。NFC/NFD/NFKC/NFKD が代表例。
- 大文字小文字区別
- 検索時に大文字と小文字を区別するかどうかの設定。
- ケースインセンシティブ
- 大文字小文字の差を無視して検索する設定。
- N-gram検索
- 文字列をN文字ごとに区切って検索する手法。誤字耐性を高める。
- ハッシュ検索
- 文字列のハッシュ値を用いて一致を検出する手法。
- トークン化と前処理の組み合わせ
- トークン化、正規化、ストップワード除去、ステミング等を組み合わせた準備作業。
- ストップワード除去
- 検索のノイズになる頻出語を除外する処理。
- 語幹化/ステミング
- 派生語を基幹語に統一して検索のマッチ率を高める処理。
- 分かち書き
- 日本語のように語境が区切られていない言語で語の境界を推定して分割する処理。
- 近接検索/ファジー検索の適用領域
- 入力ミスや表記揺れがある場合に有効な検索設定の適用領域。
- クエリ最適化
- 検索クエリの実行計画を最適化して速度と関連性を両立させる技術。
文字列検索のおすすめ参考サイト
インターネット・コンピュータの人気記事