岡田 康介
名前:岡田 康介(おかだ こうすけ) ニックネーム:コウ、または「こうちゃん」 年齢:28歳 性別:男性 職業:ブロガー(SEOやライフスタイル系を中心に活動) 居住地:東京都(都心のワンルームマンション) 出身地:千葉県船橋市 身長:175cm 血液型:O型 誕生日:1997年4月3日 趣味:カフェ巡り、写真撮影、ランニング、読書(自己啓発やエッセイ)、映画鑑賞、ガジェット収集 性格:ポジティブでフランク、人見知りはしないタイプ。好奇心旺盛で新しいものにすぐ飛びつく性格。計画性がある一方で、思いついたらすぐ行動するフットワークの軽さもある。 1日(平日)のタイムスケジュール 7:00 起床:軽くストレッチして朝のニュースをチェック。ブラックコーヒーで目を覚ます。 7:30 朝ラン:近所の公園を30分ほどランニング。頭をリセットして新しいアイデアを考える時間。 8:30 朝食&SNSチェック:トーストやヨーグルトを食べながら、TwitterやInstagramでトレンドを確認。 9:30 ブログ執筆スタート:カフェに移動してノートPCで記事を書いたり、リサーチを進める。 12:30 昼食:お気に入りのカフェや定食屋でランチ。食事をしながら読書やネタ探し。 14:00 取材・撮影・リサーチ:街歩きをしながら写真を撮ったり、新しいお店を開拓してネタにする。 16:00 執筆&編集作業:帰宅して集中モードで記事を仕上げ、SEOチェックやアイキャッチ作成も行う。 19:00 夕食:自炊か外食。たまに友人と飲みに行って情報交換。 21:00 ブログのアクセス解析・改善点チェック:Googleアナリティクスやサーチコンソールを見て数字を分析。 22:00 映画鑑賞や趣味の時間:Amazonプライムで映画やドラマを楽しむ。 24:00 就寝:明日のアイデアをメモしてから眠りにつく。
禁止文字・とは?
ここでは、禁止文字とは何か、どうして必要なのか、どんな場面で使われるのかを、初心者にも分かるように解説します。
禁止文字とは、文字列やファイル名、URL、データベースのキーなどの中で、特定の文字が使えない、またはうまく処理できないと決められている文字のことです。
代表的な禁止文字は、OSやサービスによって異なりますが、Windows のファイル名でよく問題になるものとしてバックスラッシュなどの記号が挙げられます。
なぜ禁止文字があるのか
理由は複数あります。まず、文字の解釈の混乱を避けること。例えばファイル名の区切りに使われる文字が他の用途にも使われると、システムが「この文字が区切りなのか、文字の一部なのか」を誤解してしまいます。次に、セキュリティとデータ整合性の観点です。特定の文字を悪用されると、コードの注入やパスの偽造といった危険が生じやすくなります。
禁止文字の具体例と対応表
以下の表は、よく見る禁止文字と代表的な用途・注意点のまとめです。必要なときには、アプリやサービスの公式ガイドを参照してください。
これらは一部の例であり、用途によっては他にも禁止文字が設定されます。ウェブページやアプリを作るときは、公式のドキュメントで確認することが大切です。
日常の場面での注意点
ブラウザにテキストを入力する際や、ファイルを保存する際に間違って禁止文字を使わないよう、入力時の検証を行いましょう。もし禁止文字を含む名前を受け付けてしまうと、表示が崩れたり、ダウンロードできなくなったり、サイトが正しく動かなくなることがあります。入力時の検証を行う基本的な方法として、サーバー側での検証と、クライアント側のリアルタイムチェックの両方を使うのが効果的です。
禁止文字を扱う際の実践的ポイント
ウェブサイトを作るときには、次のポイントを覚えておくと安心です。
・ファイル名は英数字とハイフン、アンダースコアを中心にする。UTF-8を使い、特殊文字を避ける。
・URL 設計では禁止文字をエスケープするか、記号を別の表現に置換して扱う。
・データベースのキーやIDには、文字数制限と文字セットの統一を守る。
禁止文字の同意語
- 禁止文字
- 特定の場面で使用を認められていない文字。入力・処理・表示の対象外になることを指します。
- 使用不可文字
- システムや仕様上、入力や処理が不可として扱われる文字。
- 使用禁止文字
- 公式に使用が禁止されている文字。
- 許可されていない文字
- 許可リストに含まれていない、使用してはいけない文字。
- 禁則文字
- 日本語の組版や改行ルールなどで禁止されている文字。
- 非許可文字
- 許可対象外の文字。基本的には使えない前提の文字です。
- ブラックリスト文字
- セキュリティやフィルタリングのブラックリストに登録されている文字。
- 排除対象文字
- 検索・検証の対象から除外される文字。
- 表示不可文字
- 画面上に表示できない、または表示が制限されている文字。
- 不許可文字
- 許可されていないと判断された文字。
- 受け付け不可文字
- 入力やデータ処理の受付対象外となる文字。
- 制限文字
- 用途や仕様上、扱いに制限がある文字。
- 不適切文字
- 文脈やポリシーで不適切と判断される文字。
- 受理不可文字
- データとして受理・保存・処理が認められない文字。
禁止文字の対義語・反対語
- 許容文字
- 禁止文字の対義語として最も基本的な表現。システムが入力として受け付け、処理してよいと認められている文字の集合。
- 使用可能な文字
- 現在の仕様や環境で実際に使える文字。禁止されていない、利用してよいとされる文字。
- 有効な文字
- データ処理上、正しく機能する文字。検証を通過し、意味的にも有効と判断される文字。
- 受け入れ可能な文字
- 入力側で問題なく受け入れられる文字。検証基準をクリアして処理できる文字。
- 許可された文字
- 権限的に使用が認められている文字。禁止ではなく、利用を許容された状態を示す語。
- 適合する文字
- 仕様に適合する、許容範囲内の文字。規則や正規表現などの条件を満たす文字。
禁止文字の共起語
- NG文字
- 禁止対象の文字そのものを指す表現。一般に入力や文書で使われるべきではない文字のこと。
- 禁止文字コード
- 禁止対象となる文字を表すコードポイント。UTF-8/UTF-16などのコード表現が含まれます。
- 入力制限
- フォームやアプリで許可・禁止を決めるルールのこと。禁止文字を含めないように設定します。
- フィルタリング
- 入力値から禁止文字を取り除く処理。実装の際に多く使われます。
- 正規表現
- 禁止文字を検出するためのパターンを定義するテクニック。/pattern/ のように記述します。
- バリデーション
- 入力値が禁止文字を含まないか等、仕様に適合しているかを確認する工程。
- エスケープ
- 危険な文字を特別な意味を持たせず扱うために前に別の文字を付けたり、表現を変えること。
- サニタイズ
- 入力を安全な形に整える処理。HTMLやデータベース用に安全化します。
- エンコード
- 文字を特定の文字コードに変換して、破損や混乱を防ぐ方法。
- Unicode
- 文字を一意に識別する標準規格。禁止文字の特定や正規化に役立ちます。
- UTF-8
- Unicodeを実装する主流のエンコード方式。ほとんどの環境で推奨されます。
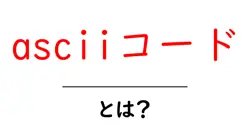
- ASCII
- 英数字と基本記号だけの文字集合。禁止文字の扱いをシンプルにする基準になることがあります。
- 半角/全角
- 半角と全角の混在を管理する観点。日本語環境では特に重要です。
- 文字種制限
- 使用できる文字の種類を限定するルールの総称。
- 記号の除外
- 特定の記号を入力から除外する設定。
- NGワード
- 不適切な語句の集合。投稿・検索時の検閲に使われます。
- 文字列正規化
- 同じ意味の文字列が異なる表現で比較される問題を揃える処理。
- クレンジング
- データを整え、不要な文字を取り除く前処理の総称。
禁止文字の関連用語
- 禁止文字
- URL・ファイル名・入力値などで使用を避けるべき文字。混乱・表示崩れ・セキュリティ上の問題を引き起こす可能性がある。
- 予約文字
- 特別な意味を持つ文字。URLやプログラム内で文字列を区切ったり特別な操作を示すため、適切に扱う必要がある。例として区切りに使われる記号が挙げられる。
- エスケープ文字
- 文字列中の特殊な文字を文字として扱うため前置く記号。代表例はバックスラッシュのような記号で、文字列処理時に用いられる。
- URLエンコード
- URLで使えない文字を%XX形式に変換して表現する処理。長さを変えずに安全に送信できる。
- パーセントエンコード
- URLエンコードと同義。文字をパーセント記法で表す手法。
- HTMLエンティティ
- HTML上で特殊文字を安全に表示・解釈するための文字列。例として &、<、> などがある。
- Unicode
- 文字を数値で表す国際規格。世界中の文字を統一して扱える基盤。
- UTF-8
- Unicodeを可変長で表現する主流のエンコーディング。URLやHTMLでも推奨される。
- ASCII
- 英数字・基本記号の基本集合。広く使われる基盤で、非ASCII文字は別のエンコーディングを使う必要がある。
- 半角文字
- 横幅が1文字として表示される文字。英数字や一部の記号が該当し、URLやDB設計で整合性を保つために意識する。
- 全角文字
- 横幅が2文字として扱われる文字。日本語を含む文字が該当し、混在すると長さ計算や表示で問題が起こることがある。
- ファイル名の禁止文字
- ファイル名で使えない文字の集合。OSにより異なるが、代表例としてバックスラッシュやスラッシュ、コロン、星印、クエスチョン、ダブルクォーテーション、小なり、大なり、パイプなどが挙げられる。
- OS別禁止文字
- OSごとに許容と禁止が異なるため、互換性を考えるなら共通の禁止文字を避けるのが安全。特にWindows系の制限を意識すると良い。
- URLスラッグ
- URLの識別子として使われる短い語。読みやすく SEO に適した形に整えるため、半角英数字とハイフン中心にするのが一般的。
- スラッグ
- URL用の短い識別子を作る処理の総称。小文字化・空白をハイフンへ変換するなどして整える。
- 正規化
- 文字列を一定の形に揃える処理。大文字小文字の統一、全角半角の統一、アクセントの整理などを含む。
- NFC/NFKC
- Unicode正規化の形式。NFCは結合文字をできるだけ1文字に統一、NFKCは互換性表現も含めて統一する。
- 文字種制限
- 許可する文字種をあらかじめ決めるルール。英字・数字・ハイフンなど用途に合わせて設定する。
- 入力検証
- ユーザー入力が仕様を満たすかを検査する前処理。禁止文字の混入を防ぎ、安定した動作を保証する。
- サニタイズ
- 悪意のある文字列を安全な形に変換・除去する処理。表示時・保存時の安全性を高める。
- エンコードとデコード
- データを別の表現へ変換したり元に戻す処理。保存・送信・表示の際に使う。
- XML/HTMLエスケープ
- XMLやHTMLで特別文字を & や < などに置換して表示・解釈を安全にする。
- URLクエリ文字列のエンコード
- クエリパラメータをURLに組み込む際に適切にエンコードするルール。
- XSS対策
- 出力時のエスケープや入力検証を組み合わせ、悪意あるスクリプトの実行を防ぐ防御策。
- SQLインジェクション対策
- データベース操作時にパラメタライズドクエリを使い、文字列の不正利用を防ぐ安全性対策。
禁止文字のおすすめ参考サイト
インターネット・コンピュータの人気記事